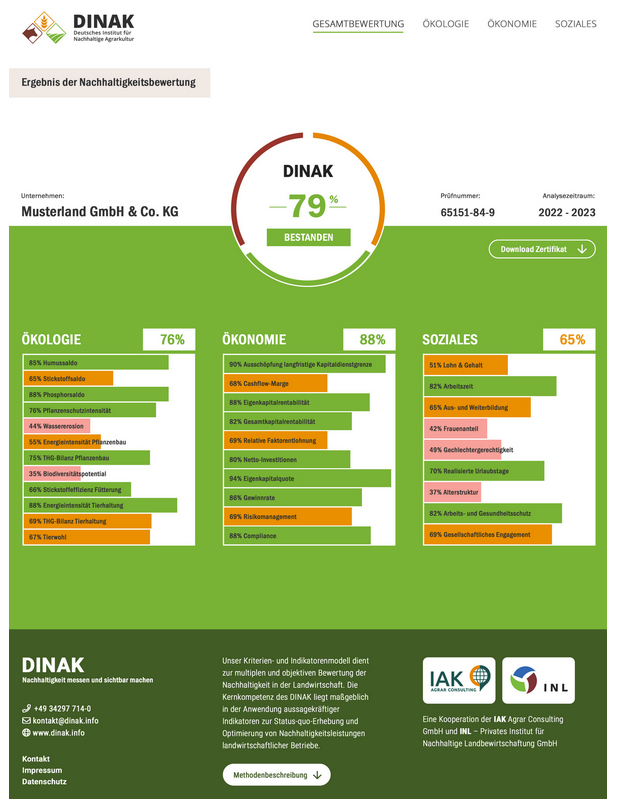
Wie nachhaltig ist ein landwirtschaftlicher Betrieb wirklich? Und wie lassen sich die Ergebnisse einer umfassenden Nachhaltigkeitsbewertung transparent entlang der gesamten Wertschöpfungskette kommunizieren? Genau diesen Fragen widmet sich das Projekt RegioNachhaltigkeit, ein gemeinsames Vorhaben des Instituts für Angewandte Informatik (InfAI) e.V, der IAK Agrar Consulting GmbH und der INL – Institut für Nachhaltige Landbewirtschaftung GmbH. In diesem Blogbeitrag geben wir Einblick in die aktuellen Fortschritte unserer Arbeit am Teilprojekt “Konzeption, Implementierung und Evaluation von Datenformaten, Prozessen und IT-Infrastruktur” durch das InfAI.
Ein System für die Nachhaltigkeitsbewertung
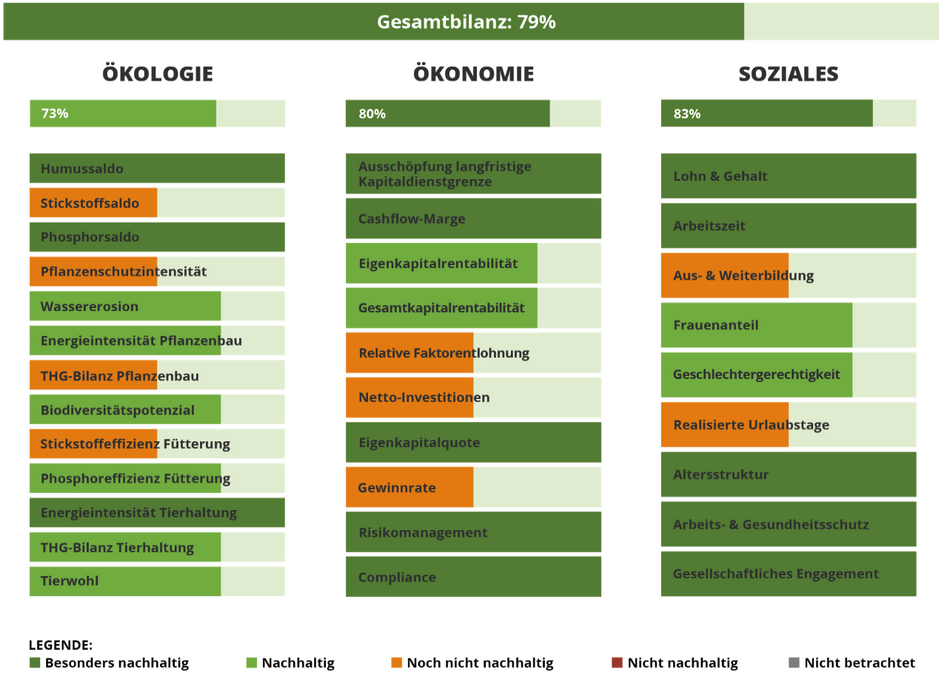
Die Basis für unsere Nachhaltigkeitsbewertung bildet das DINAK-Kriterien- und Indikatorenmodell, dass die drei zentralen Säulen der Nachhaltigkeit umfasst: Ökologie, Ökonomie und Soziales. Unsere Aufgabe im Projekt ist es, diese Bewertung in ein leistungsfähiges digitales System zu übersetzen.
Fortschritte in der technischen Entwicklung
Im letzten Jahr lag der Fokus unserer Arbeit auf der Entwicklung von Importroutinen, Datenverarbeitungsprozessen und Schnittstellen zur bestehenden Software REPRO. REPRO ist ein umfassendes System zur ökologischen und datengetriebenen Analyse von Ackerschlagkarteien der INL GmbH und spielt eine zentrale Rolle bei der Datenintegration.
Damit das Projekt effizient und strukturiert voranschreiten kann, haben wir zu Beginn des Jahres mehrere technische und organisatorische Maßnahmen umgesetzt:
- Einrichtung eines Issue-Management-Systems: Mit Redmine haben wir ein zentrales Tool für Aufgabenmanagement, Dokumentation und Zusammenarbeit geschaffen.
- Optimierung der DevOps-Prozesse und Serveradministration, um einen reibungslosen Entwicklungsprozess zu gewährleisten.
- Strukturierung des Berichtswesens, um den Projektfortschritt transparent zu dokumentieren.
Meilensteine: Datenverarbeitung und Systemintegration
In den letzten Monaten lag unser Fokus auf der Modellierung und Entwicklung von Datenverarbeitungsroutinen. Besonders für die Säulen Soziales und Ökonomie konnten wir entscheidende Fortschritte erzielen und die Anbindung an REPRO erfolgreich realisieren.
Darüber hinaus waren wir aktiv an der Konzeption der Gesamtarchitektur beteiligt. In Zusammenarbeit mit der IAK haben wir Mockups und Schnittstellen entwickelt, um die digitale Umsetzung des Systems zu unterstützen.
Nachhaltigkeitsbewertung als Webanwendung
Ein Highlight unserer bisherigen Arbeit ist die digitale Darstellung der Nachhaltigkeitsbewertung für einen Beispielbetrieb. Diese Webanwendung wurde bereits von der IAK der Öffentlichkeit präsentiert und bietet landwirtschaftlichen Betrieben einen wertvollen Einblick in ihre Nachhaltigkeitsperformance.
Durch diese digitale Aufbereitung können Betriebe:
- die Ergebnisse ihrer Nachhaltigkeitsbewertung intern analysieren,
- die Daten transparent gegenüber externen Stakeholdern (z. B. Behörden, Kunden, Zertifizierungsstellen) kommunizieren,
- sowohl aggregierte als auch detaillierte Einblicke in die drei Nachhaltigkeitsdimensionen erhalten.
Nächste Schritte: Ausbau und Optimierung
Basierend auf den bisherigen Ergebnissen konzentrieren wir uns nun auf:
- die Implementierung weiterer Systemkomponenten,
- die Schaffung zusätzlicher Schnittstellen,
- die Einbindung weiterer Datenquellen.
Nach einer ausführlichen Test- und Erprobungsphase wird das InfAI eine technische Bewertung und Optimierung des Systems vornehmen. Ziel ist es, eine robuste, praxisnahe und einfach nutzbare Lösung für nachhaltige Landwirtschaft zu schaffen.
Wir freuen uns darauf, die kommenden Entwicklungen hier auf unserer Website zu teilen und sind gespannt auf das Feedback aus der Praxis!