
Unser bereits als Preprint veröffentlichter Artikel „Assessing SPARQL capabilities of Large Language Models“ (Lars-Peter Meyer, Johannes Frey, Felix Brei und Natanael Arndt 2024) ist nun offiziell veröffentlicht in den Proceedings des Workshop „NLP4KGC: 3rd International Workshop on Natural Language Processing for Knowledge Graph Creation in conjunction with SEMANTiCS 2024 Conference”. Wir stellen dort eine Ergänzung des LLM-KG-Bench-Frameworks vor, mit der die SPARQL-Fähigkeiten von großen Sprachmodellen (englisch: Large Language Modells, kurz: LLMs; englisch: Knowledge Graph, kurz: KG, deutsch: Wissensgraph) automatisiert gemessen werden können. Das LLM-KG-Bench-Framework ist ein am InfAI e. V. entwickeltes Werkzeug zum automatisierten Bewerten der Fähigkeiten von LLMs mit Wissensgraphen umzugehen. Wenn LLMs besser mit Wissensgraphen umgehen können, würden LLMs vielleicht weniger halluzinieren sowie die Arbeit mit Wissensgraphen für Menschen erleichtern können.
Das automatisierte Messen hilft dabei neue LLMs für fachspezifische Aufgaben objektiv einordnen zu können. Und durch die Automatisierung können viele Messwiederholungen durchgeführt werden, um trotz dem nichtdeterministischen Antwortverhalten von LLMs verlässliche Ergebnisse zu erhalten.
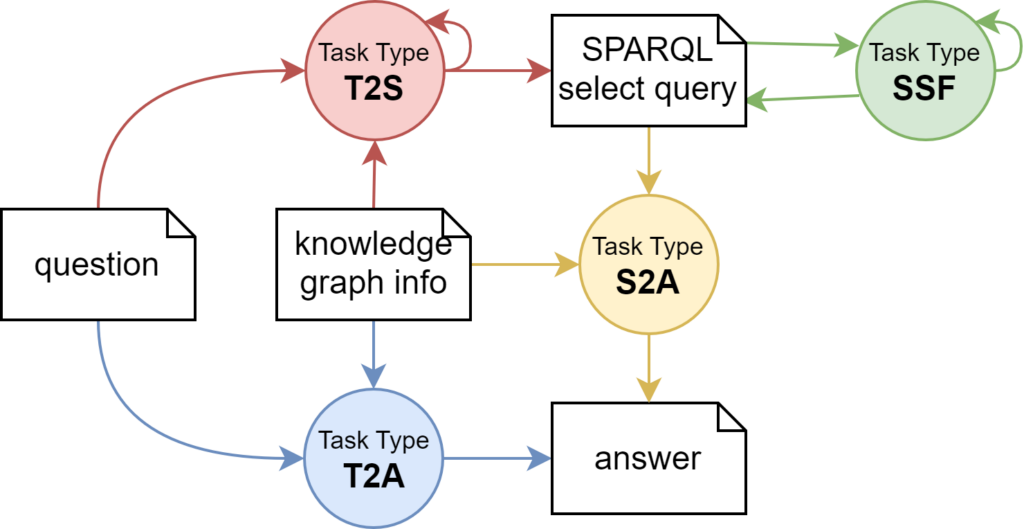
In der Welt von RDF-Wissensgraphen ist SPARQL die gebräuchlichste Schnittstelle und Abfragesprache. Deshalb geht es bei der nun vorgestellten Untersuchung um die Syntax und Semantik von SPARQL SELECT Anfragen. Diese wurden beispielhaft für insgesamt neun LLMs von OpenAI, Anthropic und Google gemessen. Basierend auf den in Grafik 1 dargestellten 4 Aufgabentypen wurden 13 verschiedene Aufgabenvarianten zu fünf verschiedenen Wissensgraphen betrachtet.
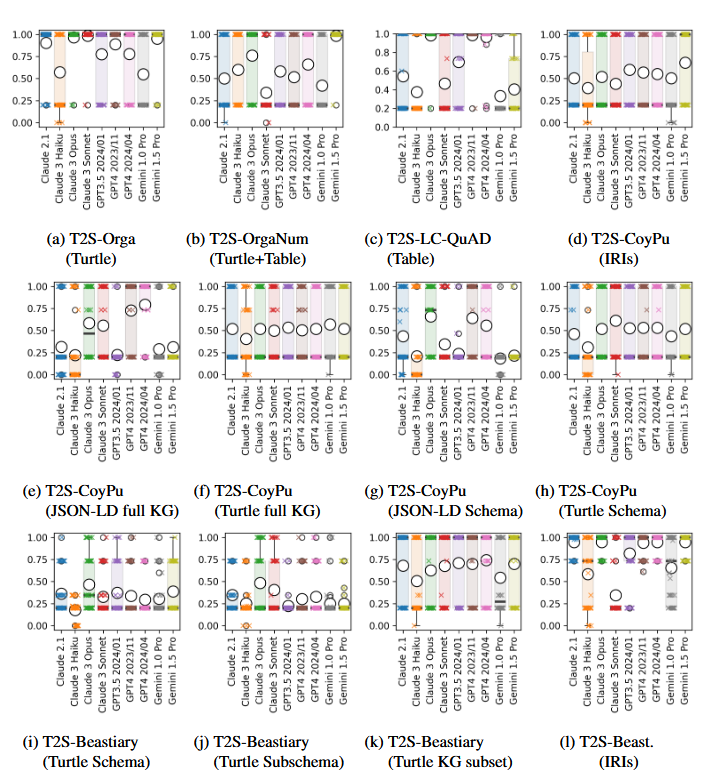
Grafik 2: Auszug aus dem Artikel mit Ergebnissen für den Bereich Text2Sparql(T2S). Die Ergebnisse sind als Boxplots gezeigt mit Kreuzen für einzelne Messwerte und Kreisen für den Mittelwert. Bei dem Score bedeutet 1 ein optimales Ergebnis, ein Score von 0,2 bedeutet ein syntaktisch richtiges aber semantisch falsches Ergebnis, ein Score von 0 wird bei Syntaxfehler vergeben. Für weitere Ergebnisse und Erläuterungen sei auf den vollständigen Artikel verwiesen.
Zentrales Ergebnis unserer Arbeit ist: Zwischen den einzelnen Aufgaben und LLMs gibt es große Unterschiede. Zusammenfassend kann man sagen, dass die besten der untersuchten aktuellen LLMs kaum Schwierigkeiten mit der Syntax haben, jedoch bei semantischen Aufgaben auf Herausforderungen stoßen. Für Details sei auf den frei verfügbaren Artikel und Repositorien verwiesen.
Die Arbeit wurde über verschiedene Projekte am InfAI e. V. gefördert: StahlDigital, ScaleTrust, KISS — KI-gestütztes Rapid Supply Network, CoyPu — Cognitive Economy Intelligence Plattform für die Resilienz wirtschaftlicher Ökosysteme.
Der Code zum LLM-KG-Bench-Frameworks ist bei Github sowie Zenodo zu finden und die vollständigen Ergebnisse wurden bei GitHub und Zenodo veröffentlicht.
Link zum Paper:
- In den Proceedings: https://ceur-ws.org/Vol-3874/paper3.pdf
- Unser Preprint: https://doi.org/10.48550/arXiv.2409.05925