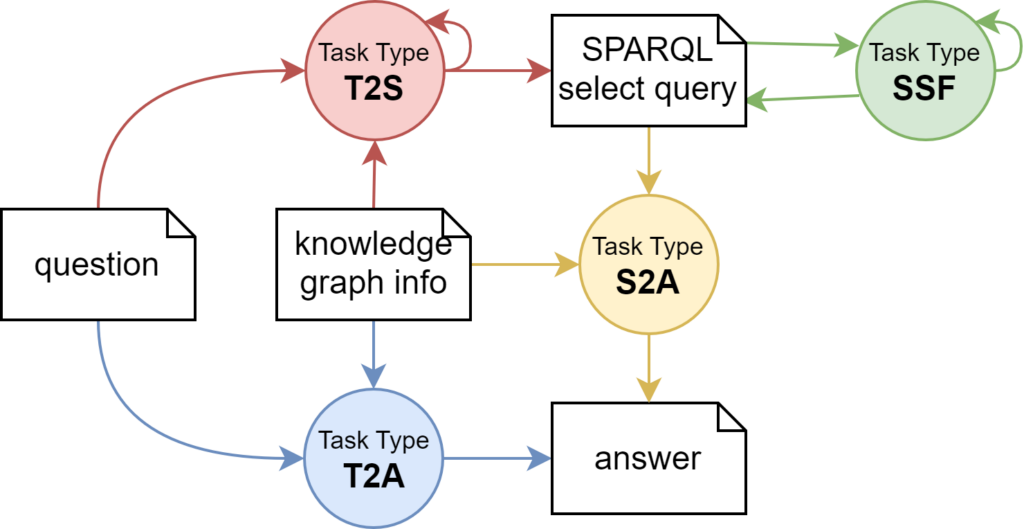
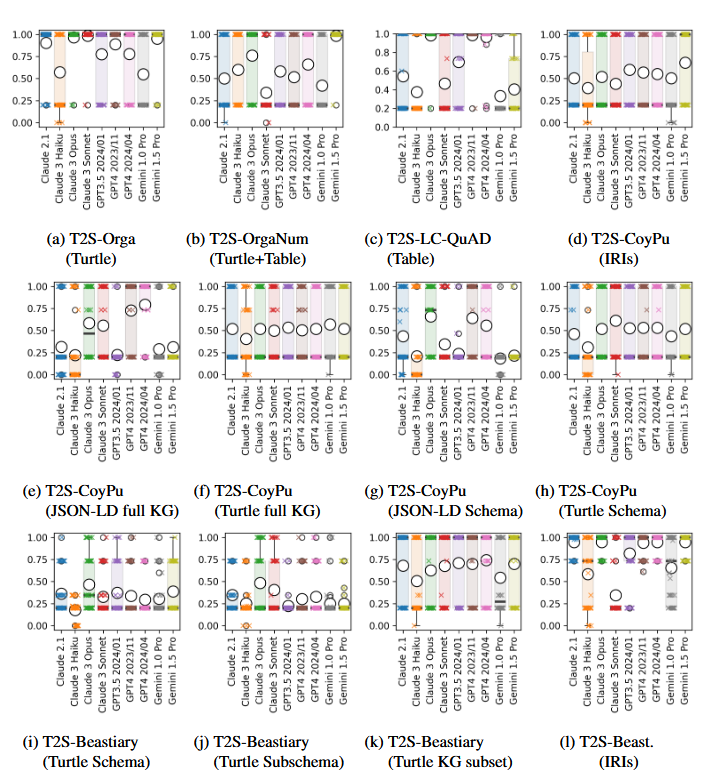
Die Abschlussveranstaltung mit über 25 Teilnehmenden des F&E‑Projekts ScaleTrust fand am 24. Februar 2026 in Leipzig statt und bot eine öffentliche Präsentation der zentralen Projektergebnisse.
Im Mittelpunkt der Veranstaltung standen die im Projekt entwickelten Ansätze, Ergebnisse und praktischen Erfahrungen sowie deren Bedeutung für den Aufbau vertrauenswürdiger Datentreuhandmodelle. Die Teilnehmenden erhielten umfassende Einblicke in Demonstratoren und konkrete Use Cases und konnten die Beiträge der beteiligten Projektpartner kennenlernen.
Besonders deutlich wurde, dass vertrauenswürdige Datentreuhandmodelle eine Schlüsselrolle für den sicheren und fairen Datenaustausch in datengetriebenen Ökosystemen spielen. Die vorgestellten Lösungen zeigten praxisnah, wie Vertrauen, Transparenz und Datenhoheit technisch und organisatorisch umgesetzt werden können.
Neben der Präsentation der Ergebnisse bot die Veranstaltung auch Raum für Austausch und Diskussion. Gemeinsam wurden zukünftige Entwicklungen, zentrale Herausforderungen und Potenziale von Datentreuhandmodellen beleuchtet.
Die Abschlussveranstaltung machte deutlich: Die im Projekt ScaleTrust entwickelten Ansätze liefern wichtige Impulse für einen verantwortungsvollen Umgang mit Daten und schaffen eine Grundlage für innovative, vertrauenswürdige Datenökosysteme.
Das InfAI beriet in dem Projekt ScaleTrust zur Architektur, unterstützte bei der Nutzung von Wissensgraphen und DCAT-AP.de und ergänzte einen Deep-Research-Agenten.

Mehr zu ScaleTrust:
ScaleTrust (Scalable Compliance and Leadership in Ethical Trusteeship) ist ein vom Bundesministerium für Forschung, Technologie und Raumfahrt (BMFTR) aus Mitteln der Europäischen Union gefördertes Forschungs- und Entwicklungsprojekt mit dem Ziel, ein rechtssicheres, skalierbares und vertrauenswürdiges Datentreuhändermodell als Grundlage fairer und dezentraler Datenökosysteme zu etablieren.
Datentreuhänder agieren dabei als neutrale Intermediäre, die Daten im Auftrag der Dateneigentümer verantwortungsvoll verwalten und kontrolliert weitergeben. Das ScaleTrust-Projekt schafft den technischen, organisatorischen und rechtlichen Rahmen für einen fairen, anwendungs‑, sektoren- und länderübergreifenden Datenaustausch, beispielhaft in der Praxis in Datenräumen wie dem Green Deal Dataspace erprobt.